前言 学习了三篇文章后,感觉这里的绕 waf 偏向于在 filename 这里做文章
通过一系列的变换,使得 waf 先解析这部分时“失败”,但在后端仍能正常处理并完成文件上传的相关操作。
Trick1 one
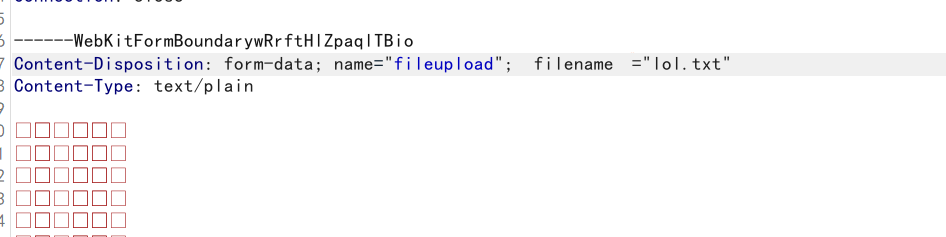
filename 周围其实是空白字符,如%20,%0a
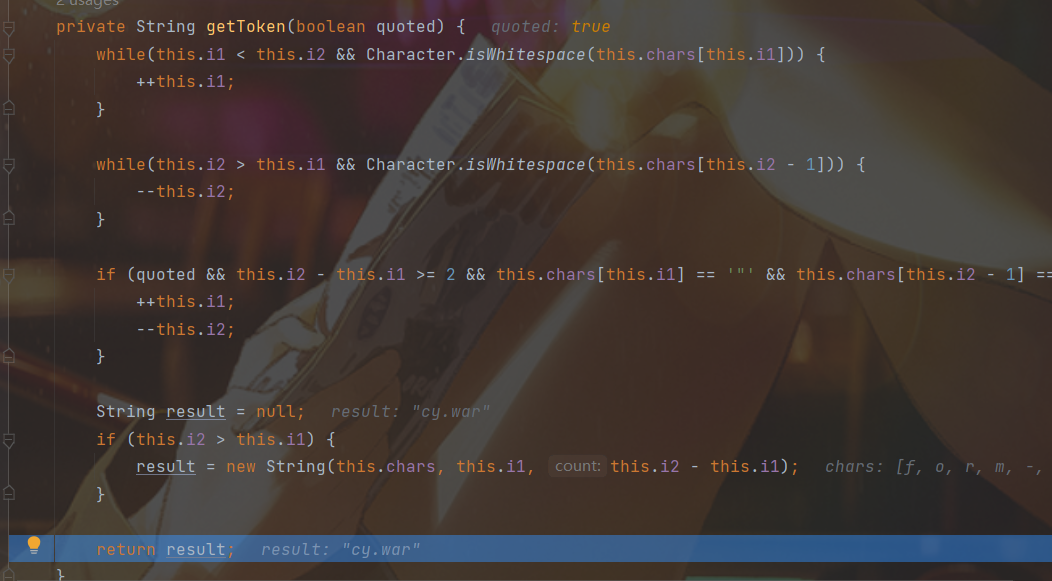
1 2 3 4 5 6 7 8 9 10 11 12 getToken:99, ParameterParser (org.apache.commons.fileupload) parseToken:162, ParameterParser (org.apache.commons.fileupload) parse:311, ParameterParser (org.apache.commons.fileupload) parse:279, ParameterParser (org.apache.commons.fileupload) parse:262, ParameterParser (org.apache.commons.fileupload) getFieldName:519, FileUploadBase (org.apache.commons.fileupload) getFieldName:503, FileUploadBase (org.apache.commons.fileupload) findNextItem:1041, FileUploadBase$FileItemIteratorImpl (org.apache.commons.fileupload) <init>:1003, FileUploadBase$FileItemIteratorImpl (org.apache.commons.fileupload) getItemIterator:310, FileUploadBase (org.apache.commons.fileupload) parseRequest:334, FileUploadBase (org.apache.commons.fileupload) parseRequest:115, ServletFileUpload (org.apache.commons.fileupload.servlet)
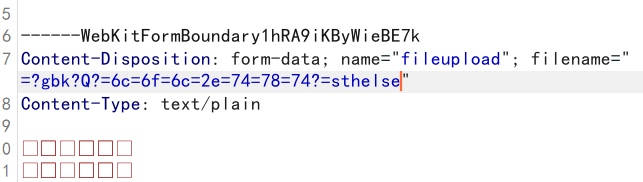
two 在org.apache.commons.fileupload.ParameterParser#parse(char[], int, int, char),对value进行了MimeUtility.decodeText操作:
要求以=?开头
之后要求还要有一个?,中间的内容为编码,也就是=?charset?
获取下一个?间的内容,这里与下面的编解码有关,Q代表Quote-print编码,B代表Base64
之后定位到最后一个?=间内容执行解码
另外decodeText还有判断\t,\n,\r,因此还可以这样
1 2 3 4 5 6 7 8 9 10 public class test { public static void main (String[] args) throws UnsupportedEncodingException { System.out.println(MimeUtility.decodeText("=?utf-8?B?dGVzdA==?=" )); System.out.println(MimeUtility.decodeText("=?gbk?Q?=31=2e?=" )); System.out.println(MimeUtility.decodeText("=?gbk?B?anNw?=" )); System.out.println(MimeUtility.decodeText("=?utf-8?B?dGVzdA==?= =?gbk?Q?=31=2e?=\t=?gbk?B?anNw?=" )); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 import base64name = "test" encode = name.encode("utf-8" ) b = base64.b64encode(encode) print ("=?utf-8?B?" +b.decode()+"?=" )res = "" for i in encode.decode("gbk" ): tmp = hex (ord (i)).split("0x" )[1 ] res += f"={tmp} " print ("=?gbk?Q?" +res+"?=" )
Trick2 one 处理文件上传中org.apache.catalina.manager.HTMLManagerServlet#upload针对获取文件名的利用
在 RFC 文档中有这么一句话:
1 Avoid including the "\" character in the quoted-string form of the filename parameter, as escaping is not implemented by some user agents, and "\" can be considered an illegal path character.
幸运的是 tomcat 可以通过函数HttpParser.unquote去进行处理,处理方式如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static String unquote (String input) { if (input == null || input.length() < 2 ) { return input; } int start; int end; if (input.charAt(0 ) == '"' ) { start = 1 ; end = input.length() - 1 ; } else { start = 0 ; end = input.length(); } StringBuilder result = new StringBuilder (); for (int i = start ; i < end; i++) { char c = input.charAt(i); if (input.charAt(i) == '\\' ) { i++; result.append(input.charAt(i)); } else { result.append(c); } } return result.toString(); }
因此可以构造如:filename=""c\y.\w\arM"这样的:
two
跟进后
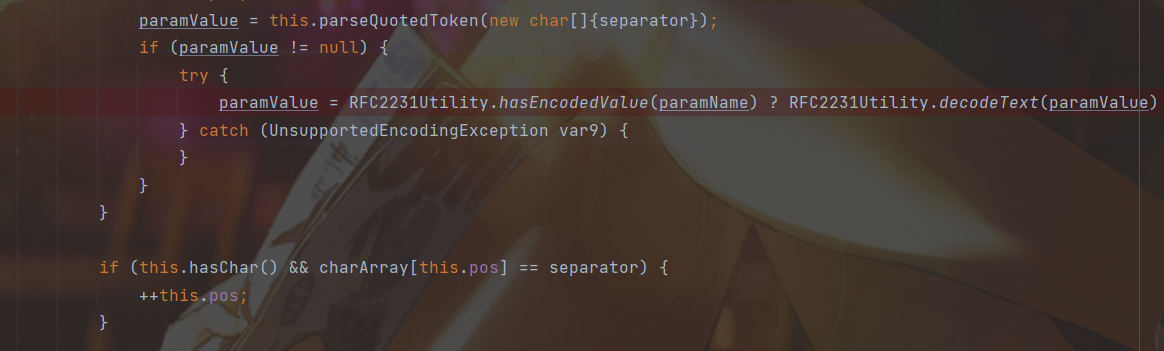
判断为真调用RFC2231Utility.decodeText,否则就是 Trick1 里的MimeUtility.decodeText
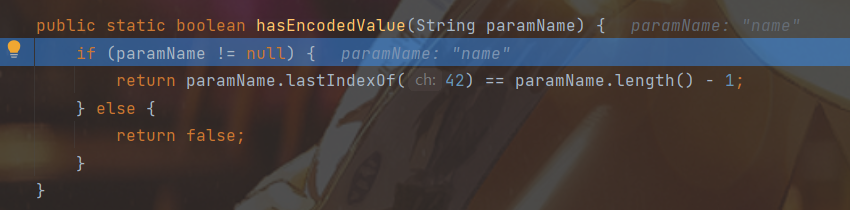
其实就是参数名最后一个是否为*,RFC 中如此描述
1 2 3 4 Asterisks ("*") are reused to provide the indicator that language and character set information is present and encoding is being used. A single quote ("'") is used to delimit the character set and language information at the beginning of the parameter value. Percent signs ("%") are used as the encoding flag, which agrees with RFC 2047. Specifically, an asterisk at the end of a parameter name acts as an indicator that character set and language information may appear at the beginning of the parameter value. A single quote is used to separate the character set, language, and actual value information in the parameter value string, and an percent sign is used to flag octets encoded in hexadecimal. For example: Content-Type: application/x-stuff; title*=us-ascii'en-us'This%20is%20%2A%2A%2Afun%2A%2A%2A
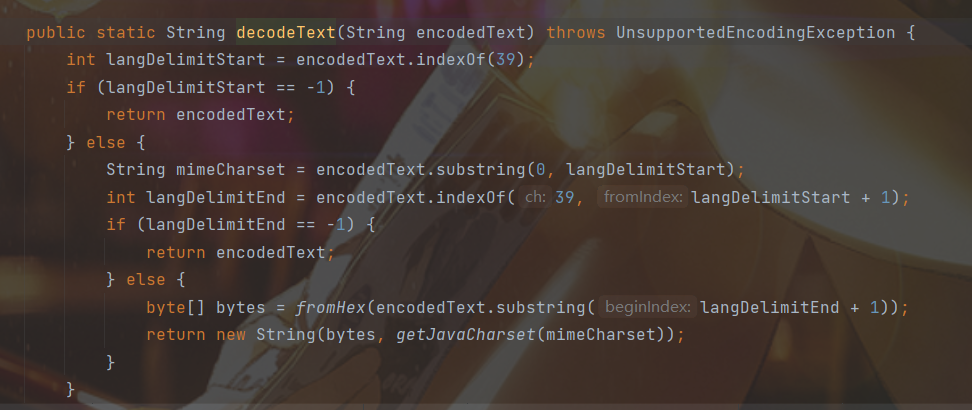
支持编码的解码
值当中可以进行url编码(fromHex解码)
@code‘‘ 中间这位language可以随便写,代码里没有用到这个的处理
列出 java 支持的编码:
1 2 3 4 5 6 7 8 9 10 11 12 Locale locale = Locale.getDefault();Map<String, Charset> maps = Charset.availableCharsets(); StringBuilder sb = new StringBuilder ();sb.append("{" ); for (Map.Entry<String, Charset> entry : maps.entrySet()) { String key = entry.getKey(); Charset value = entry.getValue(); sb.append("\"" + key + "\"," ); } sb.deleteCharAt(sb.length() - 1 ); sb.append("}" ); System.out.println(sb.toString());
最终可以这样
另外在decodeText之后
判断分隔符之后的位置,所以;可以一直加
还可以和 Trick2 中第一部分结合
three
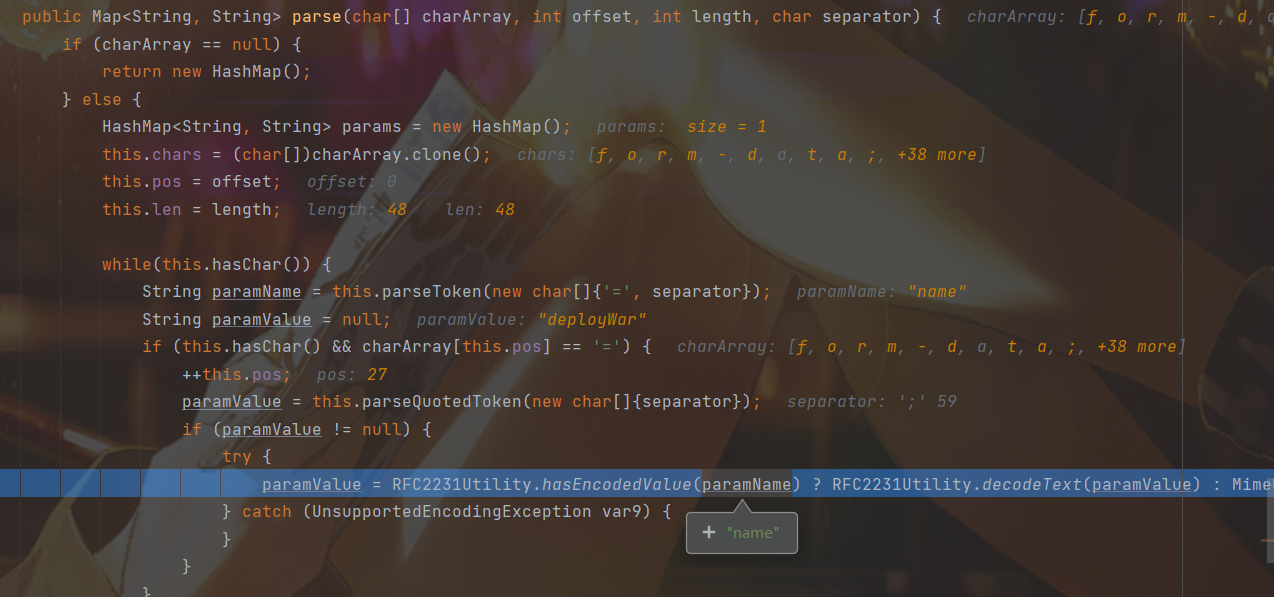
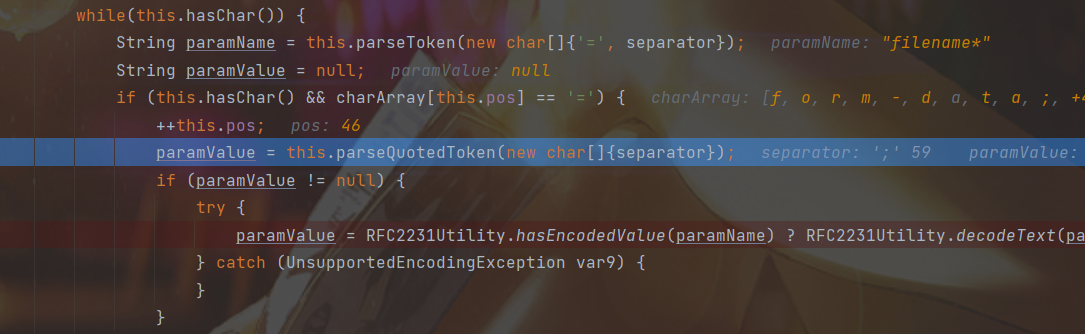
在获取值的时候paramValue = parseQuotedToken(new char[] {separator });,其实是按照分隔符;分割,值可以不用"进行包裹
关于 Spring 的更大利用面可以参考原文,还是容易理解的
Trick3
jsp如果带"符号也是可以访问到的
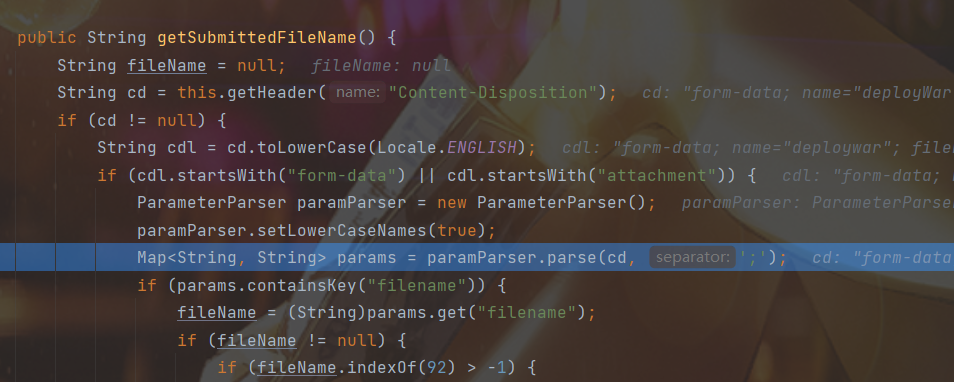
首先tomcat的org.apache.catalina.core.ApplicationPart#getSubmittedFileName的场景下,文件上传解析header的过程当中,存在while循环会不断往后读取,最终会将key/value以Haspmap的形式保存,那么如果我们写多个那么就会对其覆盖,在这个场景下绕过waf引擎没有设计完善在同时出现两个filename的时候到底取第一个还是第二个还是都处理,这些差异性也可能导致出现一些新的场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private String extractFilename (String contentDisposition, String key) { if (contentDisposition == null ) { return null ; } else { int startIndex = contentDisposition.indexOf(key); if (startIndex == -1 ) { return null ; } else { String filename = contentDisposition.substring(startIndex + key.length()); int endIndex; if (filename.startsWith("\"" )) { endIndex = filename.indexOf("\"" , 1 ); if (endIndex != -1 ) { return filename.substring(1 , endIndex); } } else { endIndex = filename.indexOf(";" ); if (endIndex != -1 ) { return filename.substring(0 , endIndex); } } return filename; } } }
由此产生的:
参考 https://y4tacker.github.io/2022/02/25/year/2022/2/Java%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E5%A4%A7%E6%9D%80%E5%99%A8-%E7%BB%95waf(%E9%92%88%E5%AF%B9commons-fileupload%E7%BB%84%E4%BB%B6)/
https://y4tacker.github.io/2022/06/19/year/2022/6/%E6%8E%A2%E5%AF%BBTomcat%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E6%B5%81%E9%87%8F%E5%B1%82%E9%9D%A2%E7%BB%95waf%E6%96%B0%E5%A7%BF%E5%8A%BF/
https://y4tacker.github.io/2022/06/21/year/2022/6/%E6%8E%A2%E5%AF%BBJava%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E6%B5%81%E9%87%8F%E5%B1%82%E9%9D%A2waf%E7%BB%95%E8%BF%87%E5%A7%BF%E5%8A%BF%E7%B3%BB%E5%88%97%E4%BA%8C/