前言
发现国内没有数据流完整性(Data-Flow Integrity)保护的相关文章,因此记录下论文学习过程
原文在:https://timharris.uk/papers/2006-osdi.pdf
背景
作者将攻击看作了在程序中滥用预期的数据流,从而写入到非预期的位置
- control-data attack:如利用缓冲区溢出漏洞覆盖返回地址、函数指针或可控数据
- non-control-data attack:在不滥用数据流的情况下覆盖安全相关的数据(当时还未在真实世界中发现,不知道现在有没有攻击属于这种分类)
文中也提到了控制流完整性(control-flow integrity)保护,其也难以防御non-control-data attacks
Data-Flow Integrity Enforcement
data-flow integrity的定义:
whenever a value is read, the definition identifier of the instruction that wrote the value is in the set of reaching definitions for the read (if there is one)
总览:首先利用静态分析得到程序的数据流图,然后对程序进行插桩,从而保证在运行时数据的流动是被数据流图所允许的,否则就直接抛出异常
我们以这段代码为例来分析文章的技术:

这段代码存在的漏洞可能为在第5行覆盖函数返回地址或变量authenticated
Static Analysis
文章基于Reaching Definition Analysis来生成数据流动图,主要包括两个分析:过程内流敏感分析和过程间流不敏感且上下文不敏感分析
我们首先看一下上述例子的中间表示,其实就是SSA:

对于代码第4行authenticated的使用,Reaching Definition Analysis会得到结果:第1行以及第8行的定义均可以抵达此处使用,而第11行结果也是如此(当然你也许会疑惑第1行的定义实际上不会到第11行呀,但请回想下Reaching Definition Analysis是may analysis,且从SSA上我们也能看出两者所在的BB存在一个跳转边)。因此,第4行和第11行authenticated的reaching definitions就是{1,8}
而过程间分析则主要根据经典的Andersen指针分析算法计算reading definitions,不考虑上下文、控制流信息以及field-sensitivity,并会将指向集合存储在文件中;其还会采集写入指令目标变量的location和identifier
那么如何计算过程间的reaching definitions呢?其实就是使用指向信息以及写入指令的相关信息。例如,在使用某个变量时,它的reaching definitions集合就是写入该变量操作的identifiers以及指针解引用可能指向该变量的写入操作的identifiers的union(感觉原文也很绕)
Instrumentation
为了计算运行时的reaching definitions,文中提出了运行时定义表(runtime definitions table,RDT),主要记录每个内存位置最后一个写入指令的identifier。因此,在读取某个值时,就可以通过其地址来从RDT中获取相应的identifier。如果其在我们静态得到的reaching definitions集合里,则是没有问题的
插入的指令格式如下:
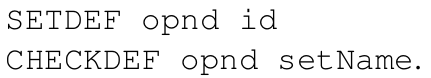
第一个就是将RDT的opnd入口设为id,第二个就是从RDT中获得opnd对应的identifier并检查是否在setName对应的reaching definitions集合中,我们来看下原始程序插桩后的代码:
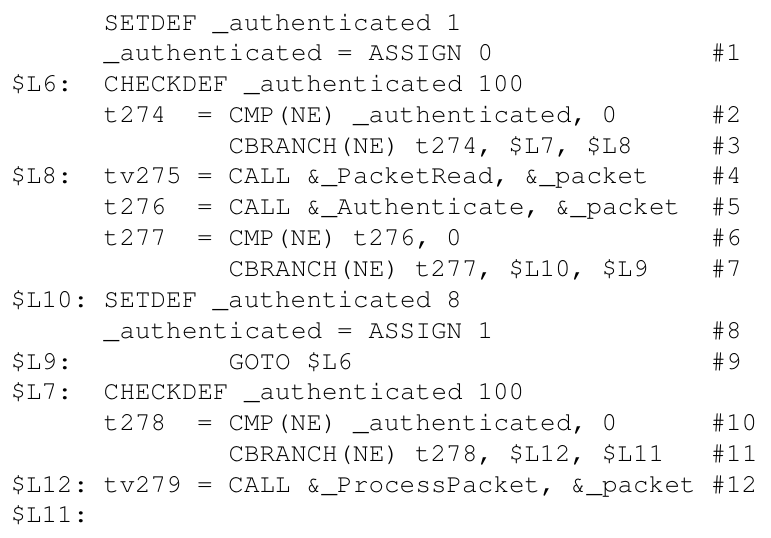
例如最开始的SETDEF设置了变量_authenticated的identifier为1(第一行),而CHECKDEF所用到的100对应的值就是静态计算的{1,8}。文章并不会对分配到寄存器的临时变量插桩,也不会对&packet进行插桩(其返回地址可以通过向frame pointer增加常量计算)
对于SETDEF _authenticated 1,对应的具体实现为:

第一行指令将目标地址写入到了ecx中,随后三行对地址的边界进行检查,没有问题的话就更新RDT
对于CHECKDEF _authenticated 100,对应的具体实现为:

因此,如果攻击者通过packet覆盖了authenticated的值(在某个流程中),这里就可以检测得到
额外的,文中还会对control-data的定义和使用插桩,比如在函数入口会设置RDT中函数的返回地址为0
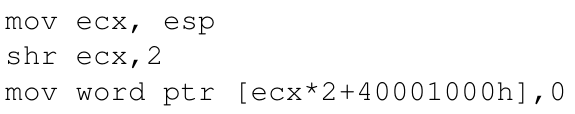
在函数返回时会进行检查
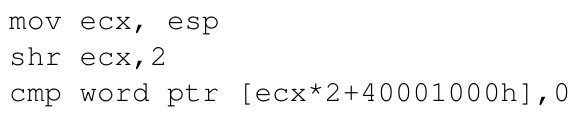
这样也能确保函数地址不会被覆盖
还有个重要的问题,就是确保攻击者不能篡改RDT、代码以及绕过文章的instrumentation:
- 对于RDT篡改,可以检测写入的地址是否在分配到RDT内存区域里,如果是的话就会产生异常(和RDT更新区别开)
- 对于代码滥用,则限制代码页只能读取
- 对于防止攻击者绕过插桩,需要防止滥用indirect control transfers的返回地址,其实就是上述函数返回地址的检测
Optimization
原生的数据流完整性执行会带来很多负担,因此需要一些列的技巧减少负担
减少重复的identifier
在相同类中安全的给definitions赋值一样的identifier
文中定义两个definitions是equivalent如果他们有相同的使用
比如authenticated 两处定义的使用都一样,因此可能简化为一个相同的identifier
移除写操作的边界检查
文中定义了一个写操作是安全的如果:
the target address is obtained by adding a small constant offset (possibly zero) to the stack pointer, frame pointer, or to the address of a global or static variable
即不会篡改RDT
移除冗余的插桩指令
假设I1和I2是任一插桩指令(SETDEF或CHECKDEF,CHECKDEF在相同数据上操作且执行时不会干预写入)
- 如果I1和I2都是SETDEF,且identifier相同,则I2是冗余的
- 如果I1和I2都是SETDEF,且没有干预对于数据的CHECKDEF,则I1是冗余的
- 如果I1是对于ID1的SETDEF,且I2是对于包含ID2集合的CHECKDEF,则I2是冗余的(移除数据使用非常接近定义的情况)
- 如果I1是对于IDS1的CHECKDEF,I2是对于IDS2的CHECKDEF,则可以将IDS2缩小到只包含IDS1的元素(溢出重复使用相同数据上的CHECKDEF)
- …
优化成员检测
连续的集合检测效率更高